Big O(no)
When does Big O actually matter?
tl;dr: Big(O) doesn’t matter for anagrams.
I’ve seen multiple YouTube shorts discussing different coding interview questions involving anagrams that have made the same incorrect “optimization.”
There are a couple of different problem statements, but the basic idea of these videos is that a “n00b” would simply use the builtin sort and compare sorted words; words that are the same sorted are anagrams of each other.
But, as these videos then go on, a “pro” would know that using an O(logn*n)
comparison sort to check if two words are anagrams is “suboptimal” when you
could do a linear, O(n) bucket sort.
But, as a “pro,” I know that Big O describes the limiting behavior of a function as it tends towards infinity.
Words don’t tend towards infinity!
Stop it!
Let’s test your “optimization”
Let’s write a program that takes an input iterable words and returns all
words that are anagrams of each other grouped together.
We need a hashable value for the key, so we take the mutable output list of
sorted(word) and cast it to a hashable tuple.
from collections import defaultdict
def anagrams(words):
ret = defaultdict(list)
for word in words:
ret[tup(sorted(word))].append(word)
return ret.values()
My little solution happens to use a defaultdict because you don’t have to
check if the key exists.
“Now let’s improve Big O!”
from collections import defaultdict
def char_frequencies(word):
ret = [0]*26
for letter in word:
ret[ord(letter) - ord("a")] += 1
return ret
def anagrams(words):
ret = defaultdict(list)
for word in words:
ret[tup(char_frequencies(word))].append(word)
return ret.values()
The above snippet now uses a linear bucket sort instead of a comparison sort. Yay, I improved Big O and got the job!
Let’s benchmark how long it takes to generate these keys for words with millions of characters:
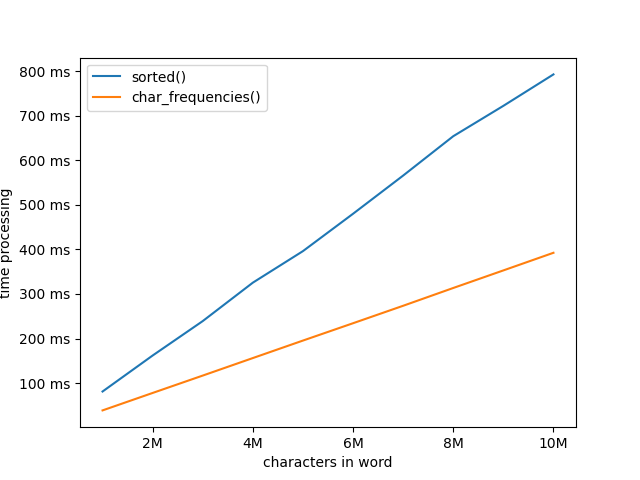
Wow, sorted is a lot slower!!!
Oh, English doesn’t have words with millions of characters in them?
I used a set of ~370k words that have been filtered to only ASCII alphabetical characters (ie only a-z).
The longest word in this list is 31 characters (“dichlorodiphenyltrichloroethane”). The vast majority of words are under 15 characters.
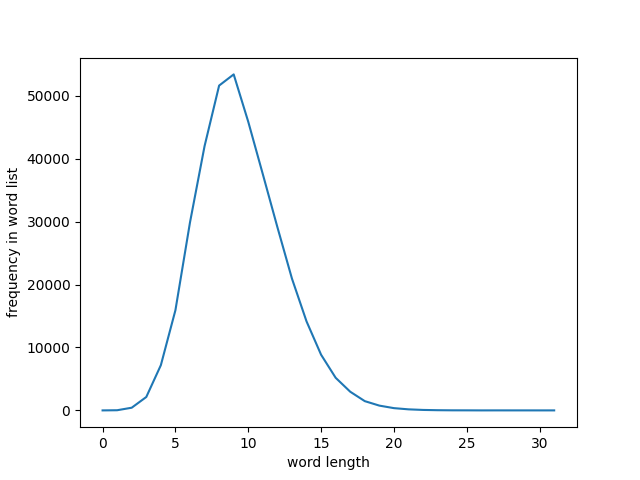
Huh… well surely better Big O is still better for this real-world dataset… right??
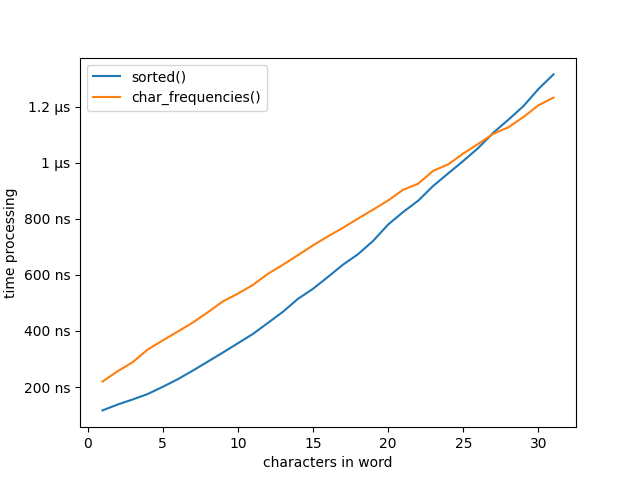
Oh.
note to self: most optimizations make code faster, not slower
There are a lot of reasons this bucket sort approach may be slower. We’re
instantiating a 26-length list every time. Memory allocation takes time. Our
sorted() solution uses an in-place sort that saves that allocation.
In fact, we see the bucket sort starts to win when we hit around 26 characters… unfortunately, very few English words are that long, and none of them are anagrams.
Our little bucket sort is fine. It’s just worse than sorted for actual
English words… if you’re going to replace a builtin you should at least be
better in any measureable way besides lines of code.
Software developer based in NYC, USA
Personal blog, opinions are my own, etc.
This site's GitHub repo
Privacy policy: I log IP address and user agent string, and also when you follow external links if Javascript is enabled in your browser. No cookies.
I do not share browsing data with third parties for any reason.
©2019-2026 Frederic Spieler